
资讯
允中 发自 凹非寺
量子位 | 公众号 QbitAIFP8通过其私有的数值默示花样,好像在保捏一定精度的同期,在大模子老师中提高老师速率、简易内存占用,最终裁汰老师老本。
AI大模子开辟系统Colossal-AI的搀杂精度老师再度升级,支柱主流的BF16(O2) + FP8(O1)的新一代搀杂精度老师决议。
仅需一转代码,即可对主流LLM模子好像得回平均30%的加快效力,裁汰相应大模子开辟老本,并保证老师管束性。
无需引入特别的手写CUDA算子,幸免了较长的AOT编译技能和复杂的编译环境成立。
开源地址:https://github.com/hpcaitech/ColossalAI
FP8搀杂精度老师低精度打算一直是GPU硬件发展趋势。
从最早的FP32,到当今通用的FP16/BF16,再到Hopper系列芯片(H100, H200, H800等)支柱的FP8,低精度打算速率越来越快,所需的内存也越来越低,非常合乎大模子时期对硬件的需求。
当今FP8搀杂精度老师影响老师摈弃的最大成分便是scaling决议,常见的决议有两种:
蔓延scaling及时scaling蔓延scaling接收之前一段技能窗口内的scaling值来测度现时scaling,同期将scaling的更新和矩阵乘法(gemm)会通起来。这种打算法度效力较高,但由于是估算的scaling,是以对管束性影响较大。
及时scaling平直接收现时的张量值来打算scaling,是以打算效力较低,然而对管束性影响较小。凭证英伟达的论说,这两种scaling决议的打算效力差距在10%以内。
Colossal-AI接收了对老师管束性影响较小的及时scaling决议,同期已毕存着不输其他蔓延scaling已毕的性能。
在单卡H100上对矩阵乘法进行的测试,不错看到矩阵的维度越大,FP8的加快效力越显著,何况Colossal-AI的已毕与Transformer Engine的性能险些一致,如图1所示。但Transformer Engine需要复杂的AOT编译环境成立和较长的编译技能。
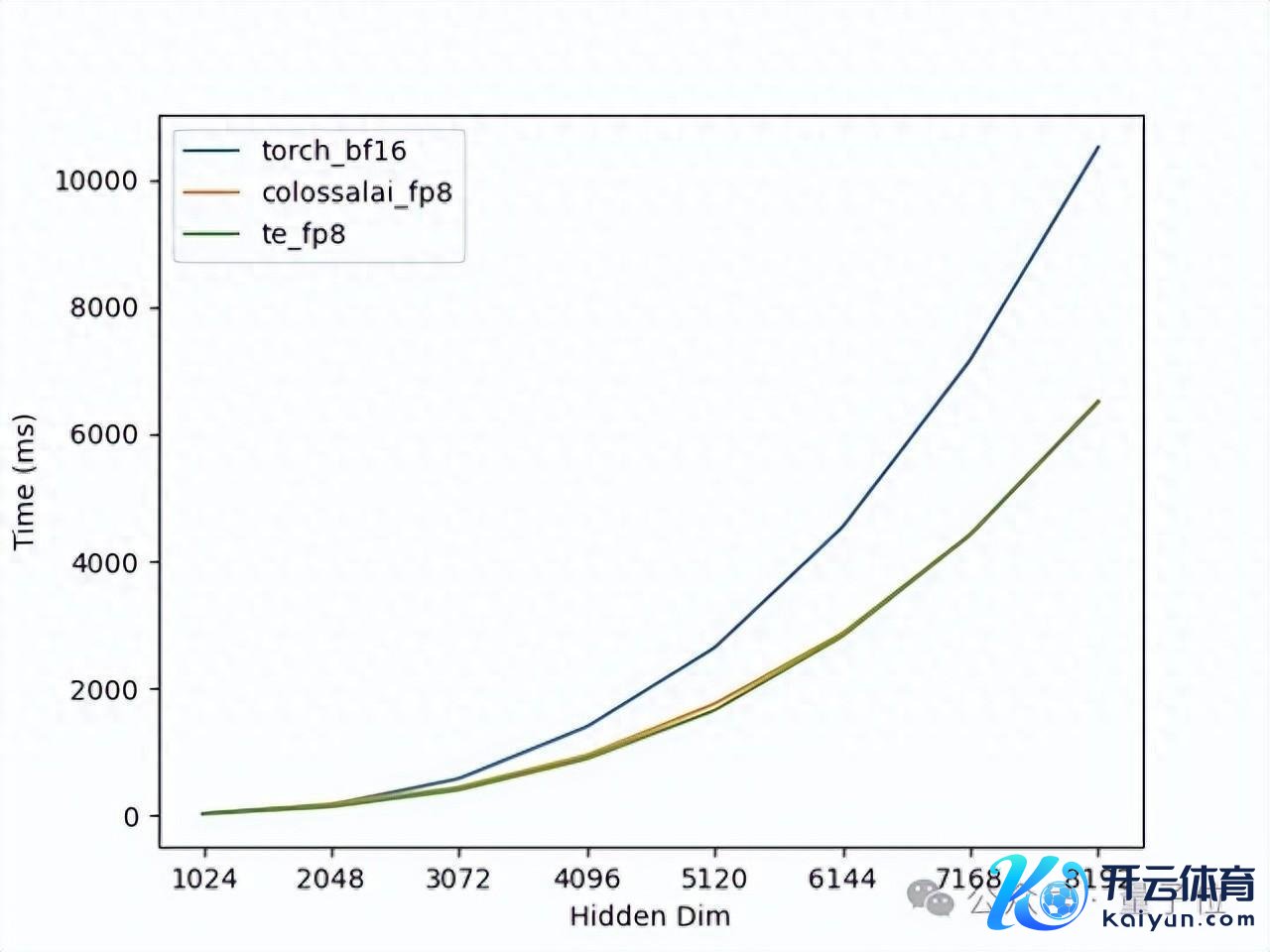
△图1. 单卡GEMM性能测试
为了实验摈弃更迫临现实,Colossal-AI平直在主流LLM上进行了施行老师的测试。
最初在H100单卡上进行了测试,以下测试中Transformer Engine (TE)接收的其默许的蔓延scaling决议。
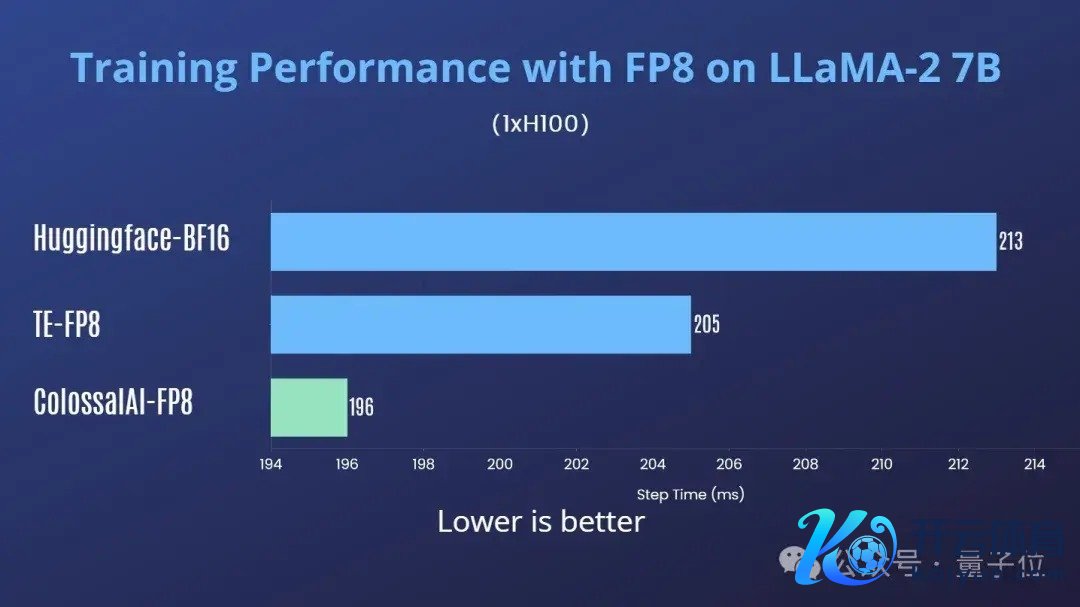
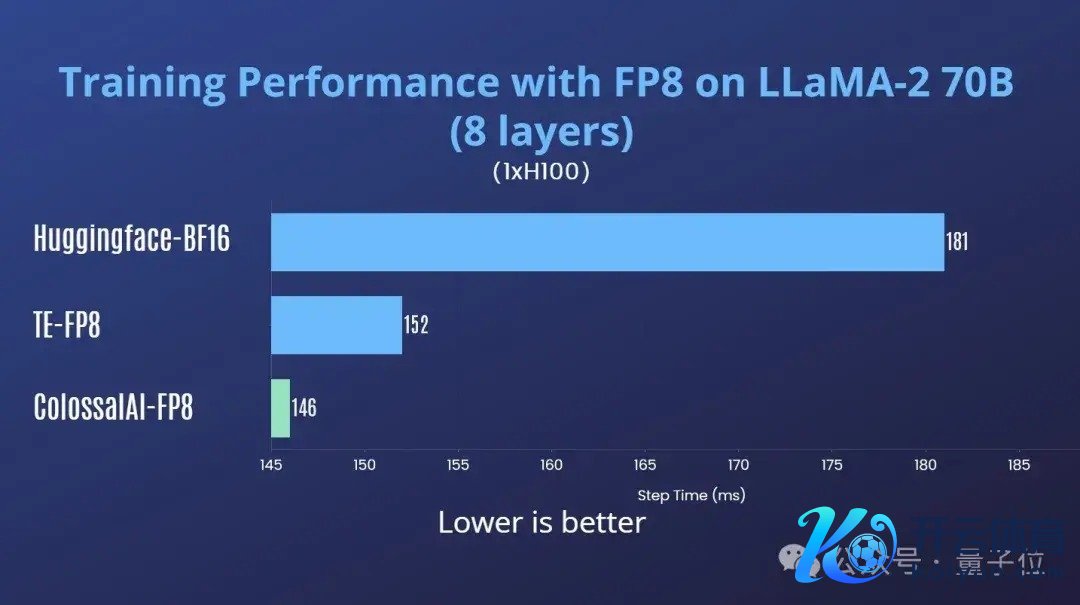
同期进行了管束性测试,不错看到FP8搀杂精度老师的loss弧线与bf16的基本一致,如图4所示:
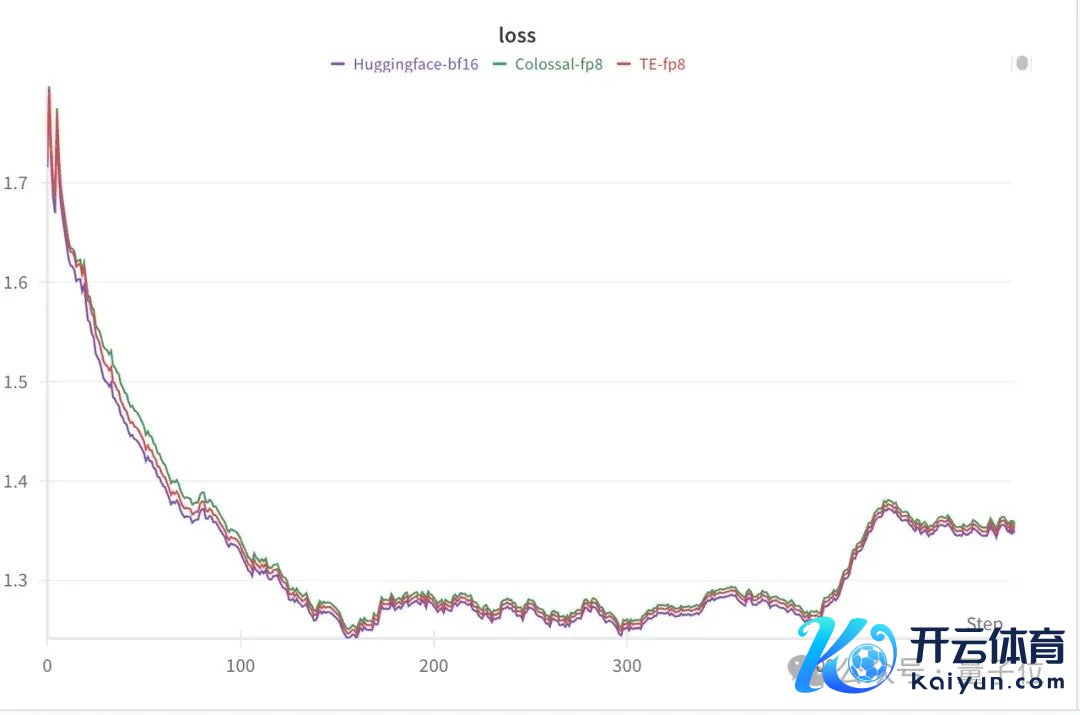
△图4. H100单卡 LLaMA2-7B 搀杂精度老师loss弧线
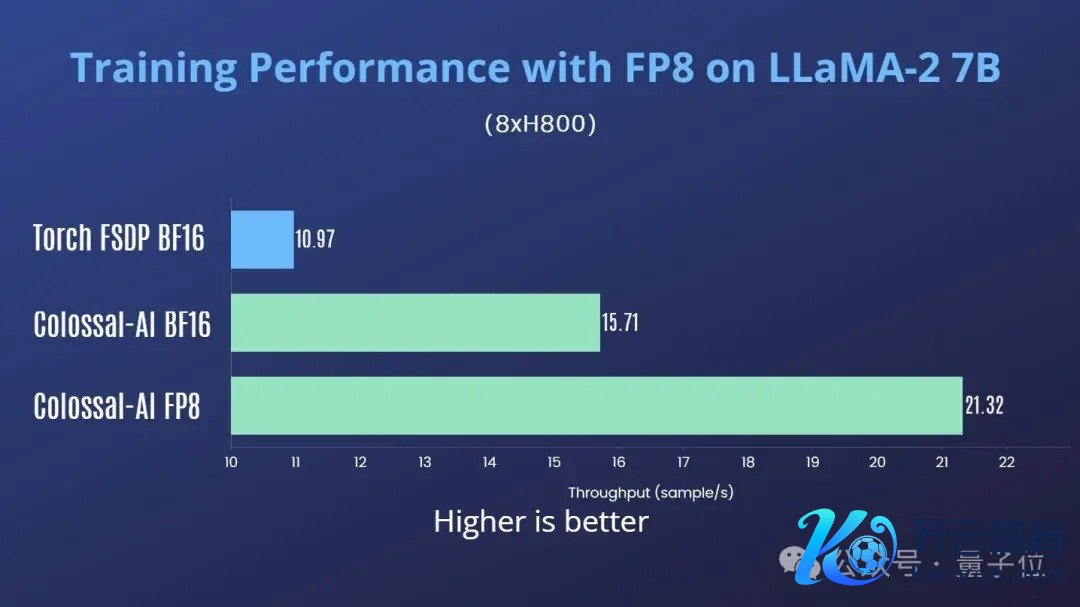
Colossal-AI还测试了H800多卡并行老师场景下的性能。在单机8卡H800上老师LLaMA2-7B,Colossal-AI FP8对比Colossal-AI BF16有35%的费解提高,对比Torch FSDP BF16有94%的费解提高。
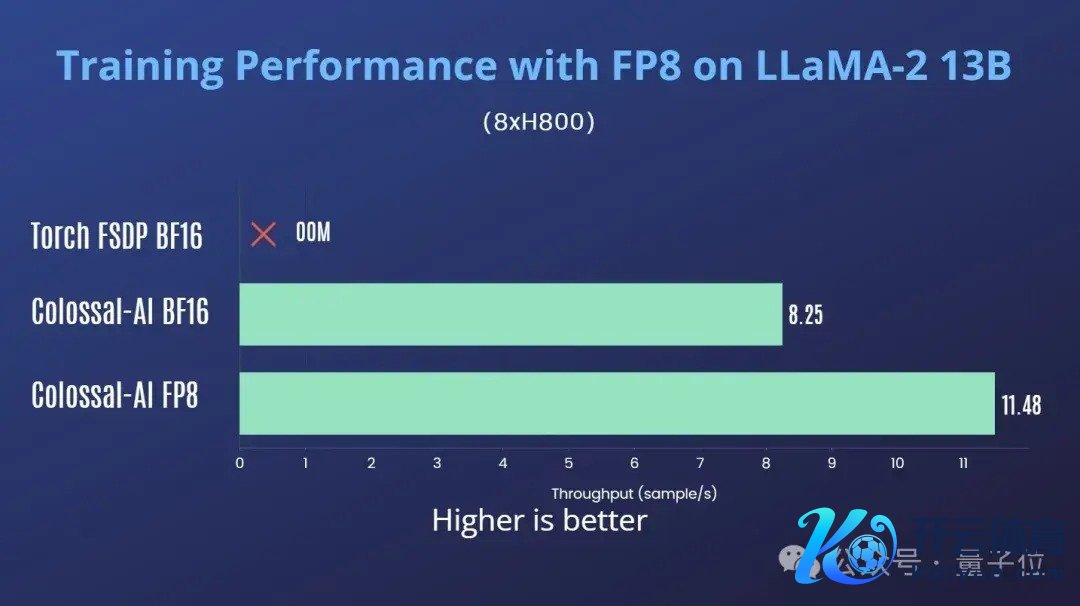
在单机8卡H800上老师LLaMA2-13B,Colossal-AI FP8对比Colossal-AI BF16有39%的费解提高。
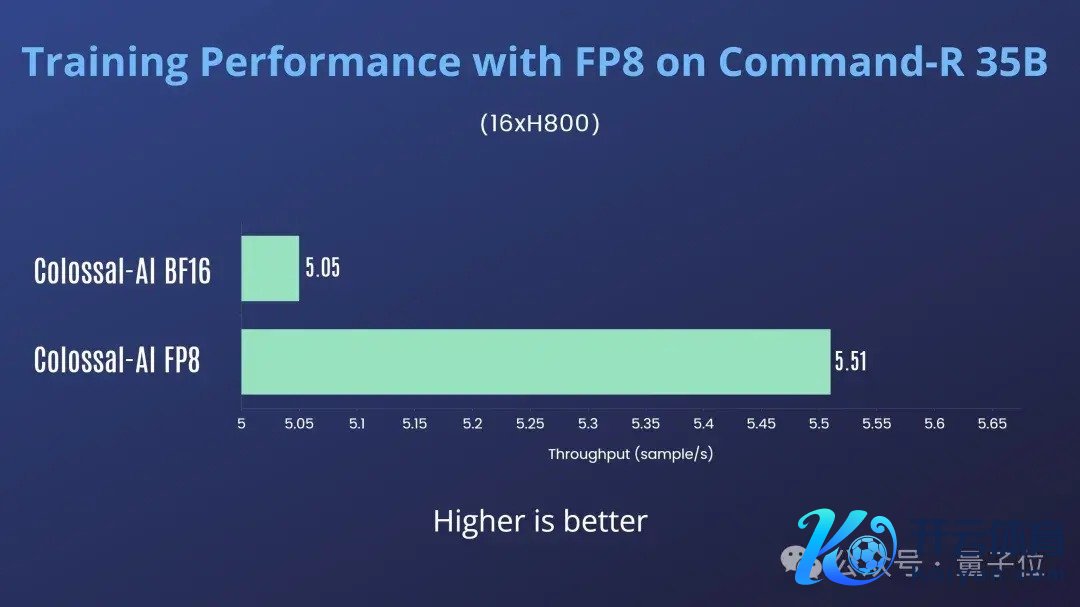
在2机16卡H800上老师Cohere Command-R 35B,Colossal-AI FP8对比Colossal-AI BF16有10%的费解提高,如图7所示:
凭证英伟达的论说和测试告诫,对FP8搀杂精度老师性能调优有一些初步的意识:
尽量少使用张量并行,用活水线并行代替张量并行模子hidden size越大,加快效力越显著矩阵乘法占比高的模子加快效力大由于上述实验中Command-R 35B接收了张量并行,是以加快效力不太显著。
Colossal-AI对FP8的支柱较为泛泛,多样并行花样王人能和FP8搀杂精度老师兼容。使用时,仅需在驱动化plugin时开启FP8即可:
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin...plugin = LowLevelZeroPlugin(..., use_fp8=True)plugin = GeminiPlugin(..., use_fp8=True)plugin = HybridParallelPlugin(..., use_fp8=True)
除此除外,无需过剩的代码和AOT编译。
开源地址:https://github.com/hpcaitech/ColossalAI
— 完 —
量子位 QbitAI · 头条号签约
怜惜咱们,第一技能获知前沿科技动态